
Hyperscience Benchmark Tests with LLMs Unveil Game-Changing Insights for Enterprise AI Success
By David Liang, Lead Product Manager, AI/ML
As we reach the midway point of 2024, Large Language Models (LLMs) remain one of the most exciting technologies for enterprise adoption. The promise of LLMs is quite compelling – the ability to deploy high performance AI models for a variety of use cases without any prior training or data preparation. However, adoption of LLMs by enterprises has been slow due to challenges ranging from hallucinations, data privacy, cost, and the need to manage different components of the tech stack ranging from inference services to monitoring / reporting.
Many organizations are now evaluating the best approach to power their AI strategy – considerations range from when to use LLMs and when to use smaller, proprietary AI models, or a combination of the two. Hyperscience has deep experience and insights in this area, both from customers and our own tests and analysis. In this blog, I’ll highlight some of those learnings.
Using Hyperscience with LLMs
While LLMs are becoming extremely pervasive, deploying and managing them at scale can be a daunting task that requires many new components to be added to your tech stack. At Hyperscience, using our Enterprise AI platform, we address some of the fundamental challenges with deploying LLMs within an enterprise environment:
- Data and prompt preparation – With our data connectors and integrations, you can easily ingest documents and emails and leverage the Hyperscience proprietary models and platform features to extract document data to feed into the LLM prompts.
- LLM output cleansing – Using our platform features like custom data types and the knowledge store, customers can normalize and structure LLM outputs for ingestion by downstream systems.
- LLM validation and reporting – With our human-in-the loop interfaces and proprietary models, you can monitor and measure accuracies for specific LLM outputs to identify when hallucinations or poor model performance occur.
- Decisioning support – Hyperscience provides a user interfaces for humans to review the LLM output and help drive workflows in downstream systems
These features have made it easy for our customers to evaluate and deploy LLMs on the Hyperscience Hypercell platform. Next, we’ll explore a customer case study of how Hyperscience helped an enterprise to adopt LLMs for a specific use case and where we see alternative AI approaches having greater success. Let’s dive in:
Using LLMs for email classification: A customer case study
Change vs Cancel: A customer case study.
A leading European travel operator was struggling with automating the processing of itinerary updates from flight carriers – a particularly challenging task especially when differentiating between Reservation Changes where the passenger has automatically been rebooked after a cancellation (see figure 1) and Cancellations where the passenger has not been rebooked yet (figure 2). As you can see, emails from different airlines have wildly different forms, formats and languages, but solving this was mission critical for their business as they require different actions, in a relatively short time window.

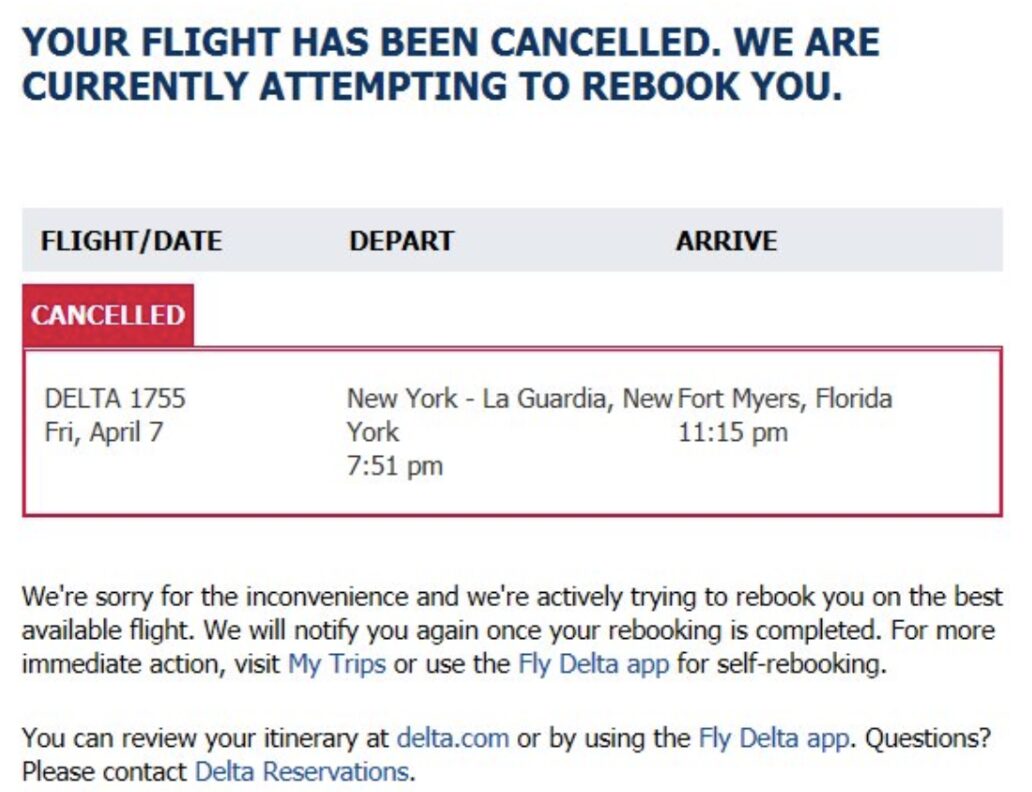
Figure 2:
Source: https://twitter.com/kasaug6/status/851956965609795585
The Hyperscience Sales Engineering team identified this as a possible use case to leverage an LLM for a couple of reasons. First, the variety of incoming data required a more general language understanding of how you interpret the email text (and intent), an area where larger parameter language models are known to perform well. In the examples shown above, it can be confusing for smaller language models to interpret the full intent of the email since both emails contain sentences with the word “cancellation” and “rebook”. Second, the inference needed was a classification task, which LLMs have shown to do well in, particularly when you ask it to categorize the email into one of a few pre-determined classes. Finally, the variation of the language and formats of the incoming data would benefit from the large corpus of data that LLMs are trained on instead of having to source and annotate enough relevant training data to train a narrower model that discerns intent correctly, every time.
Testing LLM performance demonstrated that the models were able to correctly classify Change vs Cancellation intent of the emails at a near 100% accuracy. However, the same testing also exposed where LLMs are a very poor fit: the full automation by the customer also required critical data points, such as the departure airport, arrival airport, and corresponding date / times, to be extracted into a downstream system with extreme accuracy. The data showed that the LLMs consistently confused departure and arrival airports as well as the corresponding date/times when prompted to extract that information from the wide array of formats and documents that travel companies (and their customers) use today.
Benchmarking LLMs for accuracy in data extraction and automation
In our example with the European travel operator, we found that a fine-tuned smaller language model trained on a small set of customer samples was able to identify departure and arrival airports and dates at a much higher accuracy. By combining the two AI models – using LLMs to solve the email classification problem and a fine-tuned version of Hyperscience’s smaller language model to solve the data extraction problem – we were able to achieve a 98% processing automation with a near 100% accuracy.
We have seen many examples like the one above where LLMs can solve a portion of the customer problem, but fall short on the more complex tasks of accurate data extraction. In order to understand LLM performance on these types of tasks, we conducted an experiment to evaluate several open source LLMs against four internal datasets we use to benchmark our own proprietary language models:
| Dataset | Description |
|---|---|
| Simple Invoice | A simple set of invoices where we are extracting 10 fields including Customer Name, Issuer Address, and Total Amount |
| Complex Invoice | A more challenging set of invoices where we are extracting 15 fields including more complex items such as Invoice Terms, Invoice Due Date, Shipping Amount, and Tax Amount. |
| Bill of Ladings | An internally curated dataset of Bill of Ladings where we are extracting 18 fields including Bill of Lading Number, Place of Delivery, Place of Receipt, and Total Measurement/Dimensions. |
| Government IDs | A dataset of government IDs where we are extracting 7 fields including Name, Date of Birth, and Expiration Date. |
For the sake of this exercise, we focused on open-source LLMs that were under 20B parameters to benchmark LLMs that could run natively on our customer’s infrastructure without incurring a large infrastructure spend. Many of our customers operate in environments where they cannot send their data to external, closed source LLMs (such as GPT). As a result, the models we selected for this evaluation were:
| Model | Description |
|---|---|
| Hyperscience Field Identification Model | Hyperscience’s proprietary small language model that can be fine-tuned on a small set of data for data extraction tasks. |
| Llama2 | For this evaluation, we used the 13B parameter model. https://llama.meta.com/llama2/ |
| Mistral Instruct | A 7B parameter model from Mistral https://huggingface.co/docs/transformers/en/model_doc/mistral |
| Mixtral | A 46.7B total parameter model but only uses 12.9B parameters per token https://huggingface.co/docs/transformers/en/model_doc/mixtral |
We first ran each document through Hyperscience’s proprietary Optical Intelligent Character Recognition (OICR) solution to translate the document into text. That text was then sent to each LLM in the prompt along with a question to extract a specific field. We then calculated each model’s accuracy by using string distance to compare the model’s response to the ground truth. Below are the results of our experiment:
| Hyperscience Field Identification Model | Llama2 | Mistral Instruct | Mixtral | |
|---|---|---|---|---|
| Simple Invoice | 0.934 | 0.459 | 0.474 | 0.6281 |
| Complex Invoice | 0.949 | 0.415 | 0.409 | 0.5578 |
| Bill of Ladings | 0.957 | 0.549 | 0.576 | 0.7077 |
| Government IDs | 0.975 | 0.493 | 0.536 | 0.7433 |
As a whole, Hyperscience’s smaller language models that were fine-tuned to the specific task outperformed the LLMs with accuracies around 95% when compared to the 40-75% accuracy seen with the LLMs. This may seem like a surprising result, but it validates what we have seen with our customers – that smaller, task-oriented models will outperform the general purpose LLMs that have been trained on a large corpus of data that may not be relevant for your specific use case.
When we looked deeper into the LLM errors, we noticed several patterns emerge:
- LLMs did particularly poorly when fields were not present on the documents. As an example, in our Simple Invoice dataset we had many examples of invoices without a “Vendor Code/ID” but the LLMs would still return a Vendor Code.
- LLMs did not understand the format of the field it needed to extract. As an example, in our Complex Invoice dataset, we saw examples where the LLM would return both Bill to Name and Address when just prompted to find the Name who the invoice was sent to. These were inconsistently happening and there didn’t seem to be any pattern as to when it would happen.
- The LLMs we evaluated did not have any “spatial awareness” and would group words together incorrectly. The LLMs used in this evaluation were all text-based models (in other words, these LLMs could only be sent text prompts). As a result, when translating a document into text, some spatial context is lost such as which pieces of text are not related to another or which pieces of text may be close to each other on the document. As an example, in the Bill of Lading dataset, we saw a prediction of “OOCL Canada Shanghai Long Beach CA” as a prediction for Port of Discharge when the correct answer was “Long Beach CA”
Another interesting, although not unexpected, result from this experiment was that the larger parameter large language model (Mixtral) outperformed the smaller parameter large language models. However, with larger models come higher infrastructure costs to run and may not be worth the extra money to host as they still do not outperform smaller task oriented models. With even larger models such as GPT and Gemini, you can expect to see greater accuracy but these will require you to send your data via API to third party service providers to run the inference. In the future, we plan on running similar benchmarking exercises on such closed source LLMs and multi-modal models that can natively process images or documents without prior processing.
Hyperscience: A platform for your AI automation
At Hyperscience, we are focused on helping our enterprise customers solve their challenging business automation problems with a full suite of AI and ML based features. The Hyperscience Hypercell platform empowers customers to use LLMs when they are the right solution for the task, and also enables customers to train their own proprietary models for when out of the box LLM accuracy is not sufficient. (https://hyperscience.mc-staging2.net/blog/get-ai-powered-automation-built-from-your-own-data/)
If you are interested in learning more about the unique Hyperscience approach to AI-powered enterprise automation, watch our recent product webinar and demo or reach out to us at https://hyperscience.mc-staging2.net/contact/.
