
By Jordan Hanley, Senior Solutions Engineer
Background
During discovery sessions with businesses, we often hear the pain they face in extracting information from semi-structured and human friendly, unstructured documents. Most solutions currently available in the market give businesses the ability to extract information from documents using a template centered approach where bounding boxes are drawn on a known document, marking coordinates to identify interesting data to later extract.
There has also been a trend recently for vendors of these types of platforms to offer the ability to deploy out-of-the-box models, which recognise common documents such as invoices or ID documents. These types of solutions are typically closed models that are trained using ‘someone else’s data’. Being a good option, they may not always allow businesses to directly influence the model with real world samples and although they sometimes deliver faster time to value, they also hit a glass ceiling on overall capabilities and value achieved.
Hyperscience applies a fundamentally different approach by allowing business users to train machine learning models that are grounded on enterprise samples to extract information from documents correctly and efficiently. Hyperscience customers regularly achieve 99.5% accuracy with 98% automation. This post shows how business users are training world class document extraction models using the features that Hyperscience have brought to the model training experience.
These levels of correctness allow businesses to gain the trust required for data that is driving key business decisions in downstream enterprise systems. So, at a time when a growing number of businesses are also turning their attention to the efficiencies and value that generative AI promises to deliver, it is imperative that the data which is grounding the fine tuned Large Language Models or fueling their retrieval augmented generation (RAG) systems can be trusted.
“Through 2026, those organizations that don’t enable and support their AI use cases through an AI-ready data practice will see over 60% of AI projects fail to deliver on business SLAs and be abandoned.”
Gartner (2024) – A Journey Guide to Delivering AI Success Through ‘AI-Ready’ Data
Training Data Manager (TDM)
At the heart of Hyperscience is our model training experience. Hyperscience ships with over 40 out of the box models, intended to make the user’s job as easy as possible when implementing document processing pipelines. One of the key models used when extracting information from semi-structured and unstructured documents is our identification model. The role of this model is simple, to mimic human behavior to discover the location of the interesting information on a given page. When this model is trained, users will not be required to create a template and mark coordinates of interesting information as described above.
To assist in training the most efficient and effective model in the shortest time and with the lowest amount of compute cycles Hyperscience provides a set of features with the Training Data Manager. Read on to explore just a few of these features.
Document Clustering
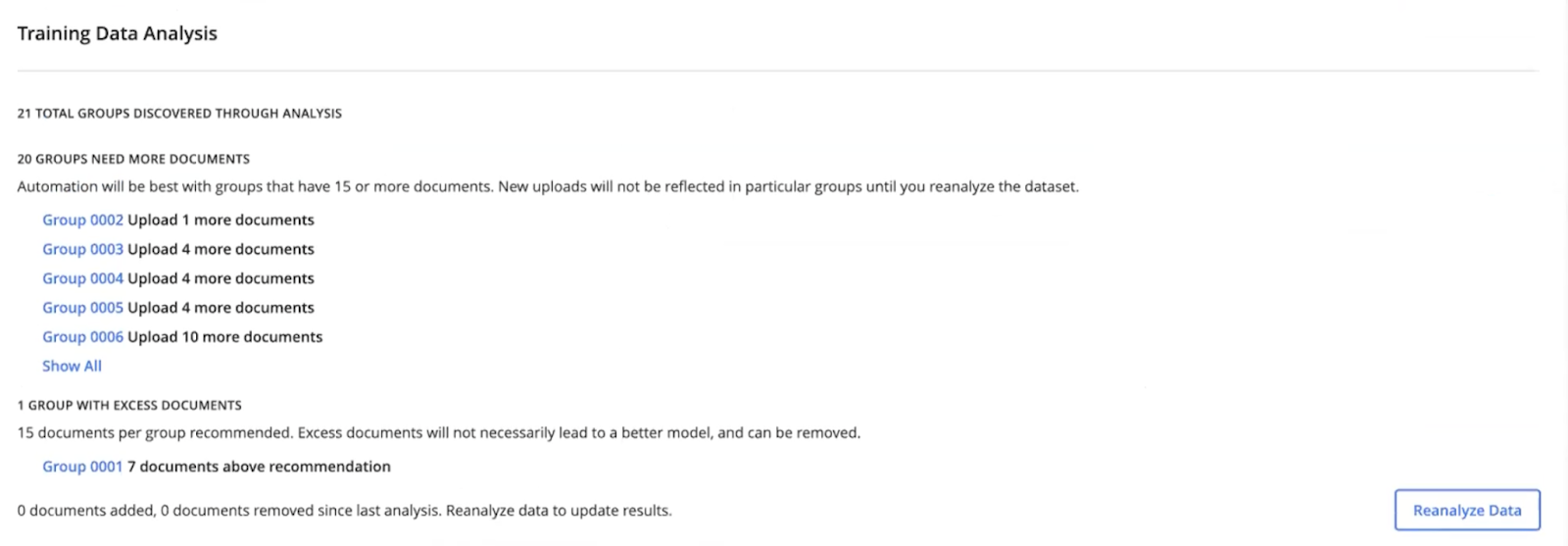
Document clustering is one of the unique features of the Hyperscience platform which guides users on selecting the best set of samples with the correct level of diversity to train the model. This AI-powered feature allows businesses to simply upload a representative sample set of production documents and allow Hyperscience to analyze these documents, group them into similar clusters and provide users with the recommendations required to add or remove samples from the training set.
Training Data Curator

Training Data Curator enhances the efficiency of the annotation process by identifying and prioritising the most impactful documents for model training. It automatically labels each document as having high or low importance based on its potential to improve the model’s performance. By focusing on a diverse and representative subset of documents, the system ensures that only the most valuable data is highlighted for annotation. This approach streamlines the process, reducing the time and effort needed while ensuring that the model is trained on data that best reflects the variety of documents expected in real-world use.
Labeling Anomaly Detection
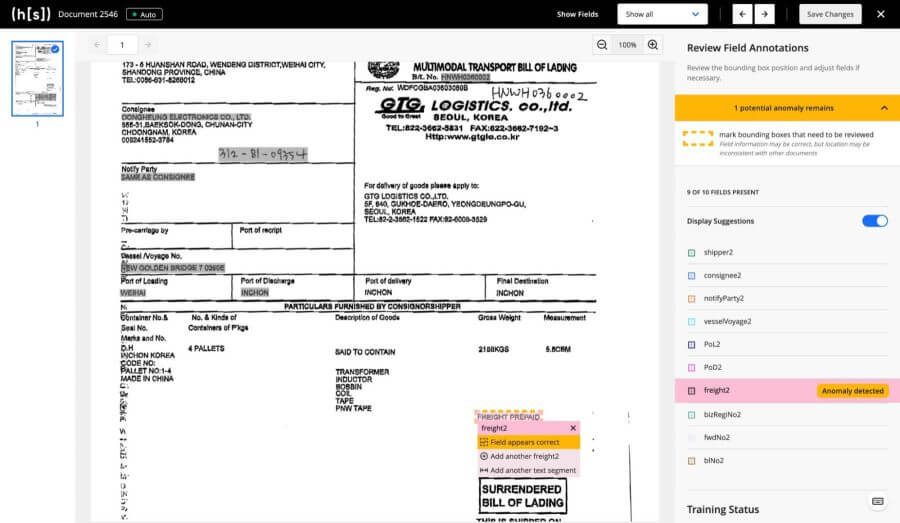
Labeling Anomaly detection helps businesses ensure correctness and efficiency in training machine learning models by flagging potential errors in document annotations. This AI-powered feature works alongside Guided Data Labeling, allowing us to streamline the process of annotating data while correcting anomalies early on. By identifying inconsistencies before training begins, we can save time and resources, reduce errors, and produce more reliable models. This approach ultimately accelerates the time-to-value, enhancing the performance and precision of machine learning systems by utilizing accurate, well-annotated data.
Conclusion
When creating document extraction pipelines and selecting tools that provide this functionality, it is important to consider the level of trust that is placed on the data that is being extracted. The proliferation of Generative AI within the enterprise relies on correct data being the source of truth. Implementing a pipeline with minimal work and hoping that value is delivered at the end is not a successful strategy.
Some up front work is required to properly define extraction techniques to ensure that the data we rely on can be a trusted source of truth. When selecting vendors or tools to assist with this up front work, we should ensure that these platforms provide us with the experience that our businesses need to make this up front work as simple and efficient as possible.
About the Author
As a member of the Hypersciences international solutions team, Jordan has wide industry experience as both a technical user and provider of automation and customer experience AI powered software. Reach out at jordan.hanley@hyperscience.com
